- Intervallarithmetik
-
Intervallarithmetik bezeichnet in der Mathematik eine Methodik zur automatisierten Fehlerabschätzung auf Basis abgeschlossener Intervalle. Dabei werden nicht genau bekannte reelle Größen x betrachtet, die aber durch zwei Zahlen a und b eingegrenzt werden können. Dabei kann x zwischen a und b liegen oder auch einen der beiden Werte annehmen. Dieser Bereich entspricht mathematisch gesehen dem Intervall [a,b]. Eine Funktion f, die von einem solchen unsicheren x abhängt, kann nicht genau ausgewertet werden. Es ist schließlich nicht bekannt, welcher Zahlenwert innerhalb von [a,b] für x eigentlich eingesetzt werden müsste. Stattdessen wird ein möglichst kleines Intervall [c,d] bestimmt, das gerade die möglichen Funktionswerte f(x) für alle
![x \in [a,b]](9/8290bddba5acf9822dcbf61f4ac67d1b.png) enthält. Durch gezielte Abschätzung der Endpunkte c und d erhält man eine neue Funktion, die wiederum Intervalle auf Intervalle abbildet.
enthält. Durch gezielte Abschätzung der Endpunkte c und d erhält man eine neue Funktion, die wiederum Intervalle auf Intervalle abbildet.Dieses Konzept eignet sich unter anderem zur Behandlung von Rundungsfehlern direkt während der Berechnung und falls Unsicherheiten in der Kenntnis der exakten Werte physikalischer und technischer Parameter vorliegen. Letztere ergeben sich oft aus Messfehlern und Bauteil-Toleranzen. Außerdem kann Intervallarithmetik dabei helfen, verlässliche Lösungen von Gleichungen und Optimierungsproblemen zu erhalten.
 Körpermasseindex für eine 1,80 m große Person in Relation zum Körpergewicht m (in Kilogramm).
Körpermasseindex für eine 1,80 m große Person in Relation zum Körpergewicht m (in Kilogramm).
Als Beispiel soll hier die Berechnung des Körpermasseindex (BMI von engl. Body Mass Index) betrachtet werden. Der BMI ist die Körpermasse in Kilogramm geteilt durch das Quadrat der Körpergröße in Metern. Zur Illustration soll die Gewichtsbestimmung (eigentlich Massebestimmung) mit Hilfe einer Badezimmerwaage erfolgen, bei der das Gewicht auf ein Kilogramm genau abgelesen werden kann. Es werden also niemals Zwischenwerte bestimmt – etwa 79,6 kg oder 80,3 kg – sondern auf ganze Zahlen gerundete Angaben. Dabei ist es natürlich sehr unwahrscheinlich, dass man wirklich exakt 80,0 kg wiegt, wenn dies angezeigt wird. Bei üblicher Rundung auf den nächstliegenden Gewichtswert liefert die Waage 80 kg für jedes Gewicht zwischen 79,5 kg und 80,5 kg. Den entsprechenden Bereich aller reellen Zahlen, die größer oder gleich 79,5 und gleichzeitig kleiner oder gleich 80,5 sind, kann einfach als Intervall [79.5,80.5] aufgeschrieben werden. Um Verwechslungen zu vermeiden setzt man meistens einen Punkt statt eines Kommas als Dezimaltrennzeichen.
Für einen Menschen, der 80 kg wiegt und 1,80 m groß ist, liegt der BMI bei ungefähr 24,7. Bei einem Gewicht von 79,5 kg und gleicher Körpergröße müsste aber nur ein Wert von 24,5 angenommen werden, wohingegen 80,5 kg schon fast 24,9 entsprechen. Der tatsächliche BMI liegt also in dem Bereich [24.5,24.9]. In diesem Fall kann der Fehler in der Praxis zwar noch vernachlässigt werden, jedoch ist das nicht bei allen Rechnungen der Fall. Beispielsweise schwankt das Gewicht auch im Laufe eines Tages, so dass der BMI hier durchaus zwischen 24 (noch normalgewichtig) und 25 (schon übergewichtig) variieren kann. Ohne detailiierte Rechnung können aber nicht immer von vornherein Aussagen darüber getroffen werden, ob ein Fehler letztendlich groß genug ist, um maßgeblichen Einfluss zu haben.
In der Intervallarithmetik wird der Bereich möglicher Ergebnisse ausdrücklich berechnet. Vereinfacht gesagt, rechnet man nicht mehr mit Zahlen, sondern mit Intervallen, die nicht genau bekannte Werte repräsentieren. Ähnlich wie ein Fehlerbalken um einen Messwert drückt ein Intervall das Ausmaß der Unsicherheit bezüglich der zu berechnenden Größe aus. Hierfür werden einfache Rechenoperationen, wie die Grundrechenarten oder trigonometrische Funktionen, für das Rechnen mit Intervallen neu definiert, um äußere Grenzen eines gesuchten Wertebereiches zu erhalten.
 Toleranzbehaftete Funktion (türkis) und Intervallnäherung (rot)
Toleranzbehaftete Funktion (türkis) und Intervallnäherung (rot)Inhaltsverzeichnis
Einführung
Das Hauptaugenmerk bei der Intervallarithmetik liegt darauf, auf möglichst einfache Art und Weise obere und untere Schranken für den Wertebereich einer Funktion in einer oder mehreren Variablen zu bestimmen. Dabei müssen diese Schranken nicht unbedingt dem Supremum bzw. Infimum entsprechen, da die genaue Berechnung dieser Werte oft zu schwierig ist. (Es lässt sich zeigen, dass diese Aufgabenstellung im allgemeinen NP-schwer ist.)
Üblicherweise beschränkt man sich auf die Behandlung abgeschlossener, reeller Intervalle, also Mengen der Form
![[a,b] = \{x \in \mathbb{R} \,|\, a \le x \le b\}](9/009e61c25ca75db45beb54b9bd69f586.png) ,
,
wobei auch
 und
und  zulässig sind. Dabei entsprechen
zulässig sind. Dabei entsprechen ![[{-\infty}, b]](6/1b6f17bdbe96fddcfc9ba2e59e35d1d0.png) und
und ![[a, {\infty}]](1/54110adab0182ce1030cf4fd752cfcb2.png) den meist halboffen geschriebenen Intervallen, die alle reellen Zahlen kleiner oder gleich b bzw. größer oder gleich a umfassen. Entsprechend bezeichnet das Intervall
den meist halboffen geschriebenen Intervallen, die alle reellen Zahlen kleiner oder gleich b bzw. größer oder gleich a umfassen. Entsprechend bezeichnet das Intervall ![[{-\infty}, {\infty}]](8/c98a0fdf110169ad80c7e7a7b14bc7eb.png) die gesamte reelle Achse.
die gesamte reelle Achse.Wie beim klassischen Rechnen mit Zahlen muss zunächst einmal definiert werden, wie die arithmetischen Operationen und elementaren Funktionen auf Intervalle anzuwenden sind. Komplexere Funktionen können dann aus diesen Grundelementen zusammengesetzt werden (Lit.: Kulisch, 1989).
Grundrechenarten
 Körpermasseindex für verschiedene Gewichte in Relation zur Körpergröße L (in Metern).
Körpermasseindex für verschiedene Gewichte in Relation zur Körpergröße L (in Metern).Zu Erläuterung wird nochmal auf das Beispiel vom Anfang zurückgegriffen. Bei der Bestimmung des Körpermasseindex spielt neben dem Gewicht auch die Körpergröße eine Rolle. Diese wird üblicherweise nur in ganzen Zentimetern gemessen werden: eine Angabe der Körpergröße von 1,80 Meter bedeutet also eigentlich eine Körpergröße irgendwo zwischen 1,795 m und 1,805 m. Diese Ungenauigkeit muss zusätzlich zu der Schwankungsbreite beim Gewicht, das zwischen 79,5 kg und 80,5 kg liegt, eingerechnet werden. Für den BMI muss nun wie gesagt die Körpermasse in Kilogramm durch das Quadrat der Körpergröße in Metern geteilt werden. Sowohl für 79,5 kg und 1,795 m als auch für 80,5 kg und 1,805 m ergibt sich dafür ungefähr 24,7. Es muss nun aber auch berücksichtigt werden, dass die fragliche Person möglicherweise nur 1,795 m groß ist bei einem Gewicht von 80,5 kg - oder auch 1,805 m bei 79,5 kg. Auch die Kombinationen aller möglichen Zwischenwerte müssen in die Betrachtung eingehen. Mit Hilfe der im Folgenden festgelegten Intervallarithmetik kann der intervallwertige BMI
tatsächlich ausgerechnet werden.
Eine Operation
 zwischen zwei Intervallen, wobei beispielsweise für Addition oder Multiplikation steht, muss die Bedingung
zwischen zwei Intervallen, wobei beispielsweise für Addition oder Multiplikation steht, muss die Bedingungerfüllen. Für die vier Grundrechenarten ergibt sich daraus
falls
 zulässig ist für alle
zulässig ist für alle ![x\in [x_1, x_2]](0/7e05f1f852af731aa65aae569d2f770f.png) und
und ![y \in [y_1, y_2]](f/04f5f11ef1ff0fc2deb95364963105b9.png) .
.Für praktische Anwendungen lässt sich dies noch weiter vereinfachen:
- Addition: [x1,x2] + [y1,y2] = [x1 + y1,x2 + y2]
- Subtraktion: [x1,x2] − [y1,y2] = [x1 − y2,x2 − y1]
- Multiplikation:
![[x_1, x_2] \cdot [y_1, y_2] = [\min(x_1 y_1,x_1 y_2,x_2 y_1,x_2 y_2), \max(x_1 y_1,x_1 y_2,x_2 y_1,x_2 y_2)]](7/5b7381798edddd8f93944535407245b1.png)
- Division:
![[x_1, x_2] / [y_1, y_2] =
[x_1, x_2] \cdot (1/[y_1, y_2])](3/b435292ef000b84313b146cdd563062c.png) , wobei 1 / [y1,y2] = [1 / y2,1 / y1] falls
, wobei 1 / [y1,y2] = [1 / y2,1 / y1] falls ![0 \notin [y_1, y_2]](1/0e1733af616576c84fcc40e54a50475e.png) .
.
Für die Division durch ein Intervall, das die Null enthält, definiert man zunächst einmal
![1/[y_1, 0] = [-\infty, 1/y_1]](8/7e8b4c1dd3a4dcf1c1fbebad3278e3c0.png) und
und ![1/[0, y_2] = [1/y_2, \infty]](0/85090382090dd355f0ff73b324efd3e2.png) .
.
Für y1 < 0 < y2 gilt
![1/[y_1, y_2] = [-\infty, 1/y_1] \cup [1/y_2, \infty]](9/17981ec43d59462284f7bb1cc55ef5db.png) , so dass man eigentlich
, so dass man eigentlich ![1/[y_1, y_2] = [-\infty, \infty]](b/2db552be615995e0eff8d7455fdc454d.png) setzten müsste. Dadurch verliert man allerdings die Lücke (1 / y1,1 / y2) und damit wertvolle Informationen. Üblicherweise rechnet man daher mit den Teilmengen
setzten müsste. Dadurch verliert man allerdings die Lücke (1 / y1,1 / y2) und damit wertvolle Informationen. Üblicherweise rechnet man daher mit den Teilmengen ![[-\infty, 1/y_1]](7/617b090573d63fa2959626b82038654e.png) und
und ![[1/y_2, \infty]](1/8e15dd96f6c5d8140a546eecdaff5468.png) einzeln weiter.
einzeln weiter.Weil innerhalb einer Intervallrechnung auch mehrere solcher Aufspaltungen auftreten können, ist es manchmal sinnvoll, das Rechnen mit sogenannten Multi-Intervallen der Form
![\textstyle \bigcup_{i=1}^l [x_{i1},x_{i2}]](8/238635c74ecc803649ad66663e0f9ff6.png) zu systematisieren. Die entsprechende Multi-Intervall-Arithmetik pflegt dann eine disjunkte Menge von Intervallen und sorgt dann beispielsweise auch dafür, sich überschneidende Intervalle zu vereinigen (Lit.: Dreyer, 2005).
zu systematisieren. Die entsprechende Multi-Intervall-Arithmetik pflegt dann eine disjunkte Menge von Intervallen und sorgt dann beispielsweise auch dafür, sich überschneidende Intervalle zu vereinigen (Lit.: Dreyer, 2005).Da man eine Zahl
 als das Intervall [r,r] interpretieren kann, erhält man sofort eine Vorschrift zur Kombination von intervall- und reellwertigen Größen.
als das Intervall [r,r] interpretieren kann, erhält man sofort eine Vorschrift zur Kombination von intervall- und reellwertigen Größen.Mit Hilfe dieser Definitionen lässt sich bereits der Wertebereich einfacher Funktionen, wie
 bestimmen. Setzt man beispielsweise a = [1,2], b = [5,7] und x = [2,3], so ergibt sich
bestimmen. Setzt man beispielsweise a = [1,2], b = [5,7] und x = [2,3], so ergibt sich![f(a,b,x) = ([1,2] \cdot [2,3]) + [5,7] = [1\cdot 2, 2\cdot 3] + [5,7] = [7,13]](d/50d50810fce884a80b7e739af846f82a.png) .
.
Interpretiert man f(a,b,x) als Funktion einer Variablen x mit intervallwertigen Parametern a und b, dann lässt sich die Menge aller Nullstellen dieser Funktionenschar leicht bestimmen. Es gilt dann
![f([1,2],[5,7],x) = ([1,2] \cdot x) + [5,7] = 0\Leftrightarrow [1,2] \cdot x = [-7, -5]\Leftrightarrow x = [-7, -5]/[1,2]](e/f6eaa2e8adadfa031d54069e2ea99857.png) ,
,
die möglichen Nullstellen liegen also im Intervall [ − 7, − 2.5].
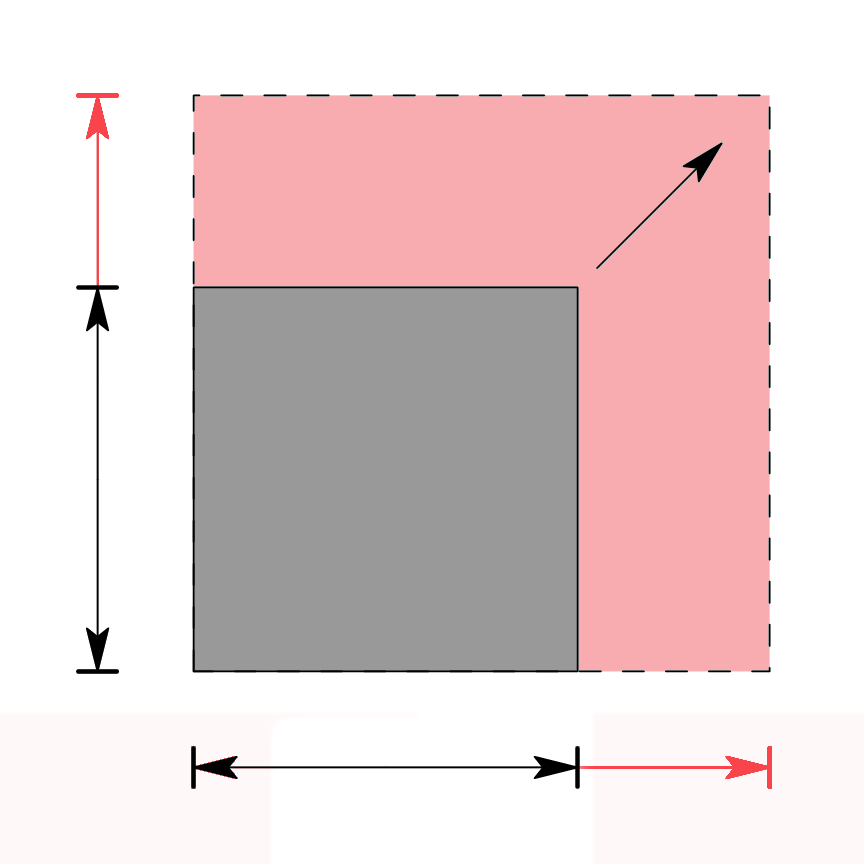
 Multiplikation positiver Intervalle
Multiplikation positiver IntervalleWie im obigen Beispiel kann die Multiplikation von Intervallen oft auf die Multiplikation nur zweier Zahlen zurückgeführt werden. Es gilt nämlich
![[x_1, x_2] \cdot [y_1, y_2] = [x_1 \cdot y_1, x_2 \cdot y_2]](6/9b6d4da5b57e632c78a25d4112247f56.png) , falls
, falls  .
.
Die Multiplikation lässt sich hier als Flächenbestimmung eines Rechtecks mit variierenden Kantenlängen interpretieren. Das intervallwertige Ergebnis deckt dann alle Werte von der kleinst- bis zu größtmöglichen Fläche ab.
Entsprechendes gilt, wenn eines der beiden Intervalle ganz im nicht-positiven und das andere ganz im nicht-negativen Bereich der reellen Achse liegt. Generell muss bei der Multiplikation noch beachtet werden, dass das Ergebnis sofort auf
gesetzt werden muss, falls unbestimmte Werte, wie  auftreten. Dies tritt z. B. bei einer Division auf, bei der Zähler und Nenner beide Null enthalten.
auftreten. Dies tritt z. B. bei einer Division auf, bei der Zähler und Nenner beide Null enthalten.Notation
Um intervallwertige Größen leichter in Formeln zu erkennen, zweckentfremdet man die eckigen Klammern zur „Markierung“.
Dementsprechend bezeichnet
![[x] \equiv [x_1, x_2]](8/d986ee08e36a8a9de2f83fef895f2c2d.png) ein Intervall und die Menge aller reellen Intervalle wird als
ein Intervall und die Menge aller reellen Intervalle wird alsabgekürzt. Für eine Box oder einen Vektor von Intervallen
![\big([x]_1, \ldots , [x]_n \big) \in [\mathbb{R}]^n](1/af1ef50763619f06ef7aa31803f2357d.png) verwendet man zusätzlich fetten Schriftschnitt:
verwendet man zusätzlich fetten Schriftschnitt: ![[\mathbf{x}]](f/6ffc2d70016cb37c824ee3e066f1bc22.png) .
.Bei einer derart kompakten Notation ist zu beachten, dass [x] nicht mit einem sogenannten uneigentlichen Intervall [x1,x1] verwechselt wird, bei dem obere und untere Grenze übereinstimmen.
Elementare Funktionen
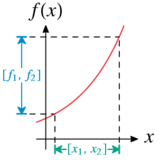 Wertebereich einer monotonen Funktion
Wertebereich einer monotonen FunktionUm auch Funktionen mit Intervallmethoden behandeln zu können, deren Terme sich nicht aus den Grundrechenarten ergeben, muss man auch noch weitere elementare Funktionen für Intervalle neu definieren. Dabei nutzt man vorhandene Monotonieeigenschaften aus.
Für monotone Funktionen in einer Variablen lässt sich der Wertebereich ebenfalls leicht bestimmen. Ist
 monoton steigend oder fallend in einem Intervall [x1,x2], dann gilt für alle Werte
monoton steigend oder fallend in einem Intervall [x1,x2], dann gilt für alle Werte ![y_1, y_2 \in [x_1, x_2]](c/f3c5b84ca53e105b20f60b5f538662c2.png) mit
mit  die Ungleichung
die Ungleichung , bzw.
, bzw.  .
.
Den Wertebereich des Intervalls
![[y_1, y_2] \subseteq [x_1, x_2]](e/dbedf31e35c737c928cb6d1b340e7bc7.png) erhält man durch Auswertung der Funktion an den Endpunkten y1 und y2:
erhält man durch Auswertung der Funktion an den Endpunkten y1 und y2:![f([y_1, y_2]) = \left[\min \big \{f(y_1), f(y_2) \big\}, \max \big\{ f(y_1), f(y_2) \big\}\right]](8/6185ea314f29da92b50df9d120824aef.png) .
.
Daher lassen sich folgende Intervallisierungen elementarer Funktionen leicht definieren:
- Exponentialfunktion:
![a^{[x_1, x_2]} = [a^{x_1},a^{x_2}]](4/ee471657f7db21c40645b02022689668.png) , für a > 1,
, für a > 1, - Logarithmus:
![\log_a\big( {[x_1, x_2]} \big) = [\log_a {x_1}, \log_a {x_2}]](8/6f8d91fae8186d7f3d8040f589f39139.png) , für positive Intervalle [x1,x2] und a > 1
, für positive Intervalle [x1,x2] und a > 1 - Ungerade Potenzen:
![{[x_1, x_2]}^n = [{x_1}^n,{x_2}^n]](a/31ac86d74250e36b22ad756c0998ce53.png) , für ungerade
, für ungerade  .
.
Es ist außerdem noch wichtig, den Wertebereich für gerade Potenzen bestimmen zu können. Im Gegensatz zur üblichen Numerik ist es hier nicht sinnvoll, die Berechnung auf die Multiplikation zurückzuführen. Beispielsweise bewegt sich xn für
![x \in [-1,1]](7/547db7d2339cfb3345123313fe6a4981.png) innerhalb des Intervalles [0,1], wenn
innerhalb des Intervalles [0,1], wenn  . Versucht man [ − 1,1]n aber durch Multiplikationen der Form
. Versucht man [ − 1,1]n aber durch Multiplikationen der Form ![[-1,1]\cdot \ldots \cdot [-1,1]](9/bc92fbf2ca7eda39c66822bd11148501.png) zu bestimmen, so erhält man in jedem Fall als Ergebnis [ − 1,1].
zu bestimmen, so erhält man in jedem Fall als Ergebnis [ − 1,1].Sinnvoller ist es hier, die Parabel xn als Zusammensetzung einer monoton fallenden (für x < 0) und einer monoton steigenden Funktion (für x > 0) zu betrachten. Es gilt also für gerade
:![{[x_1, x_2]}^n = [x_1^n, x_2^n]](9/bd91b8e667e16ec5551c64d2c4b9bc68.png) , falls
, falls  ,
,![{[x_1, x_2]}^n = [x_2^n, x_1^n]](0/610e66f3bd84ce62b7630ec86450072a.png) , falls x2 < 0,
, falls x2 < 0,![{[x_1, x_2]}^n = [0, \max \{x_1^n, x_2^n \} ]](d/c1d5e1af2f1a437991d8215be7538279.png) , sonst.
, sonst.
Allgemeiner kann man sagen, dass es für stückweise monotone Funktionen ausreicht, diese an den Endpunkten x1,x2 eines Intervalls [x1,x2], sowie an den in [x1,x2] enthaltenen sogenannten kritischen Punkten auszurechnen. Die kritischen Punkte entsprechen hierbei den Stellen, an denen sich die Monotonieeigenschaften ändern.
Dies lässt sich z. B. auf Sinus und Kosinus anwenden, die zusätzlich an Stellen
 bzw.
bzw.  für alle
für alle  ausgewertet werden müssen. Hierbei spielen höchstens fünf Punkte eine Rolle, da man als Ergebnis sofort [ − 1,1] festlegen kann, wenn das Eingangsintervall mindestens eine ganze Periode enthält. Außerdem müssen Sinus und Kosinus lediglich an den Randpunken neu evaluiert werden, da die entsprechenden Werte an den kritischen Stellen – nämlich -1, 0 , +1 – vorab abgespeichert werden können.
ausgewertet werden müssen. Hierbei spielen höchstens fünf Punkte eine Rolle, da man als Ergebnis sofort [ − 1,1] festlegen kann, wenn das Eingangsintervall mindestens eine ganze Periode enthält. Außerdem müssen Sinus und Kosinus lediglich an den Randpunken neu evaluiert werden, da die entsprechenden Werte an den kritischen Stellen – nämlich -1, 0 , +1 – vorab abgespeichert werden können.Intervallerweiterungen allgemeiner Funktionen
Im Allgemeinen findet man für beliebige Funktionen keine derart einfache Beschreibung des Wertebereiches. Man kann diese aber oft auf Intervalle ausdehnen. Wenn
 eine Funktion ist, die einen reellwertigen Vektor auf eine reelle Zahl abbildet, dann nennt man
eine Funktion ist, die einen reellwertigen Vektor auf eine reelle Zahl abbildet, dann nennt man ![[f]:[\mathbb{R}]^n \rightarrow [\mathbb{R}]](f/5cf8f591c4816696c9a06a29e2489eeb.png) eine Intervallerweiterung von f, wenn gilt
eine Intervallerweiterung von f, wenn gilt \supseteq \{f(\mathbf{y}) | \mathbf{y} \in [\mathbf{x}]\}](0/d10046897d3d61604f1bd4bfabe96429.png) .
.
Dies definiert die Intervallerweiterung nicht eindeutig. So sind beispielsweise sowohl
 =[e^{x_1}, e^{x_2}]](5/c45a99431d6f89d22bce7ae4c91fa753.png) als auch
als auch  =[{-\infty}, {\infty}]](b/5eb96d37b0c85d0363cbafa0662f9a24.png) zulässige Erweiterungen der Exponentialfunktion. Da möglichst scharfe Erweiterungen gewünscht sind, also solche, die so genau wie möglich den gesuchten Wertebereich approximieren, wird man in diesem Fall eher [f] wählen, da sie sogar den exakten Bereich bestimmt.
zulässige Erweiterungen der Exponentialfunktion. Da möglichst scharfe Erweiterungen gewünscht sind, also solche, die so genau wie möglich den gesuchten Wertebereich approximieren, wird man in diesem Fall eher [f] wählen, da sie sogar den exakten Bereich bestimmt.Die natürliche Intervallerweiterung erhält man, indem man in der Funktionsvorschrift
 die Grundrechenarten und elementaren Funktionen durch ihre intervallwertigen Äquivalente ersetzt.
die Grundrechenarten und elementaren Funktionen durch ihre intervallwertigen Äquivalente ersetzt.Die Taylor-Intervallerweiterung (vom Grad k ) einer k + 1 mal differenzierbaren Funktion f ist definiert durch
 :=](f/b9fe9cb271dd43261965cbd6dcff25b1.png)
![f(\mathbf{y}) + \sum_{i=1}^k\frac{1}{i!}\mathrm{D}^i f(\mathbf{y}) \cdot ([\mathbf{x}] - \mathbf{y})^i + [r]([\mathbf{x}], [\mathbf{x}], \mathbf{y})](7/b07d304643ca94fa4c5ad3b338fff435.png) ,
,
für ein
![\mathbf{y} \in [\mathbf{x}]](9/3492087ebf8a85314cbc63a4c3a14332.png) ,
,wobei
 das Differential i-ter Ordnung von f am Punkt
das Differential i-ter Ordnung von f am Punkt  und [r] eine Intervallerweiterung des Taylorrestgliedes
und [r] eine Intervallerweiterung des Taylorrestgliedesbezeichnet.
 Mittelwert-Erweiterung
Mittelwert-ErweiterungDa der Vektor ξ zwischen
 und mit
und mit ![\mathbf{x}, \mathbf{y} \in [\mathbf{x}]](7/ca7f38a5a1c2b7ec41993ba1ef0747b1.png) liegt, lässt sich ξ ebenfalls durch abschätzen. Üblicherweise wählt man für den Mittelpunkt des Intervallvektors und die natürliche Intervallerweiterung zur Abschätzung des Restgliedes.
liegt, lässt sich ξ ebenfalls durch abschätzen. Üblicherweise wählt man für den Mittelpunkt des Intervallvektors und die natürliche Intervallerweiterung zur Abschätzung des Restgliedes.Den Spezialfall der Taylor-Intervallerweiterung vom Grad k = 0 bezeichnet man auch als Mittelwert-Intervallerweiterung. Für eine Intervallerweiterung der Jacobi-Matrix
](2/1b2512ddf2ba489d9e9b24b410f4a363.png) erhält man hier
erhält man hier :=
f(\mathbf{y}) + [J_f](\mathbf{[x]}) \cdot ([\mathbf{x}] - \mathbf{y})](6/206548e6dbf567f6b3cc568c6e2fe525.png) .
.
Eine nichtlineare Funktion kann so durch lineare Funktionen eingegrenzt werden.
Intervallverfahren
Die Methoden der klassischen Numerik können nicht direkt für die Intervallarithmetik umgesetzt werden, da hierbei Abhängigkeiten meist nicht berücksichtigt werden.
Gerundete Intervallarithmetik
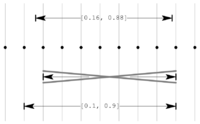 Äußeres Runden bei Gleitkommazahlen
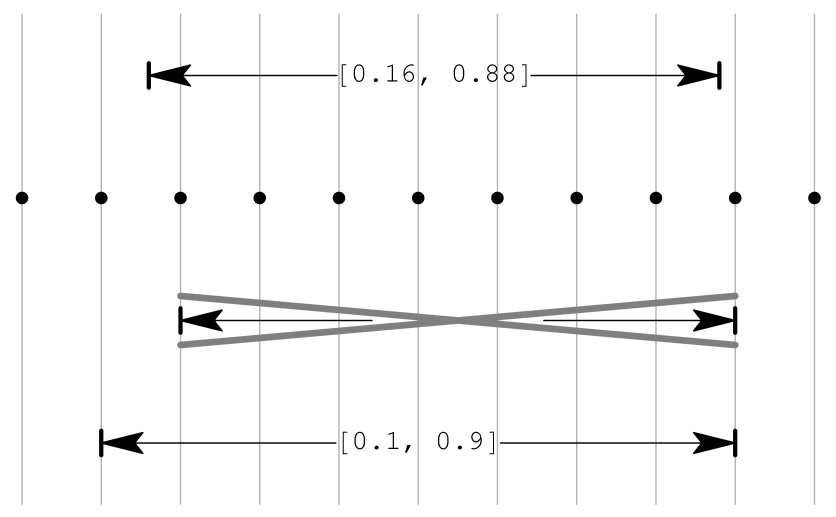
Äußeres Runden bei GleitkommazahlenUm effizient mit Intervallen rechnen zu können, muss eine konkrete Implementierung kompatibel zum Rechnen mit Gleitkommazahlen sein. Die oben definierten Operationen basieren auf exakter Arithmetik, die bei schnellen numerischen Lösungsverfahren nicht zur Verfügung steht. Der Wertebereich der Funktion f(x,y) = x + y für
![x \in [0.1, 0.8]](e/98e4fe400f13514f319e82090de06669.png) und
und ![y \in [0.06, 0.08]](b/c4b199a851930dcd973a377639468264.png) wäre beispielsweise [0.16,0.88]. Führt man die gleiche Rechnung mit einstelliger Präzision durch, so würde das Ergebnis üblicherweise zu [0.2,0.9] gerundet. Da aber
wäre beispielsweise [0.16,0.88]. Führt man die gleiche Rechnung mit einstelliger Präzision durch, so würde das Ergebnis üblicherweise zu [0.2,0.9] gerundet. Da aber ![[0.2, 0.9] \not\supseteq [0.16, 0.88]](f/06fef1e2caf0aaf0ce9e4d2f4b84e26b.png) würde dieser Ansatz den Grundprinzipien der Intervallarithmetik widersprechen, da ein Teil des Wertebereiches von f([0.1,0.8],[0.06,0.08]) verloren geht. Stattdessen ist hier die nach außen gerundete Lösung [0.1,0.9] vorzuziehen.
würde dieser Ansatz den Grundprinzipien der Intervallarithmetik widersprechen, da ein Teil des Wertebereiches von f([0.1,0.8],[0.06,0.08]) verloren geht. Stattdessen ist hier die nach außen gerundete Lösung [0.1,0.9] vorzuziehen.Die Norm IEEE 754 definiert neben Standarddarstellungen binärer Gleitkommazahlen auch genaue Verfahren für die Durchführung von Rundungen. Demnach muss ein zu IEEE 754 konformes System dem Programmierer neben dem mathematischen Runden (zur nächsten Gleitkommazahl) noch weitere Rundungsmodi bereitstellen: immer aufrunden, immer abrunden und Rundung gegen 0 (Ergebnis betragsmäßig verkleinern).
Das benötigte nach außen Runden lässt sich also durch entsprechendes Umschalten der Rundungseinstellungen des Prozessors beim Berechnen von oberer und unterer Grenze bewerkstelligen. Alternativ kann dies durch Hinzuaddition eines geeigneten schmalen Intervalls [ε1,ε2] erreicht werden.
Abhängigkeitsproblem und Einhüllungseffekt
 Überschätzung des Wertebereiches
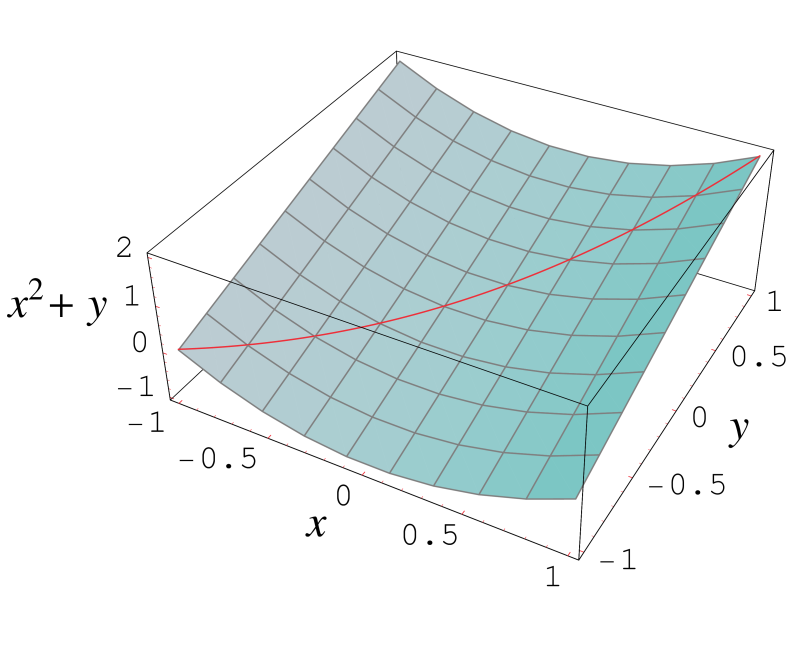
Überschätzung des WertebereichesDas sogenannte Abhängigkeitsproblem ist ein Haupthindernis bei der Anwendung der Intervallarithmetik. Obwohl der Wertebereich der elementaren arithmetischen Operationen und Funktionen mit Intervallmethoden sehr genau bestimmt werden kann, gilt dies nicht mehr für zusammengesetzte Funktionen. Falls ein intervallwertiger Parameter mehrfach in einer Rechnung auftritt, wird jedes Auftreten unabhängig voneinander behandelt. Dies führt zu einer ungewollten Aufblähung der resultierenden Intervalle.
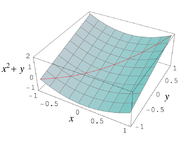 Unabhängige Betrachtung jedes Auftretens einer Variablen
Unabhängige Betrachtung jedes Auftretens einer VariablenZur Illustration sei eine Funktion f durch den Ausdruck f(x) = x2 + x gegeben. Der Wertebereich dieser Funktion über dem Intervall [ − 1,1] beträgt eigentlich [ − 1 / 4,2]. Um die natürliche Intervallerweiterung zu erhalten, rechnet man aber [ − 1,1]2 + [ − 1,1] = [0,1] + [ − 1,1] = [ − 1,2], was einen etwas größeren Bereich ergibt. In der Tat berechnet man eigentlich Infimum und Supremum der Funktion h(x,y) = x2 + y über
![x,y \in [-1,1]](5/3b54ecc061d737eade094ed5bd827010.png) . Hier würde man also besser eine alternative Formulierung für f verwenden, die die Variable x nur einmal verwendet. In diesem Fall kann man den Ausdruck f(x) = x2 + x einfach durch quadratische Ergänzung zu
. Hier würde man also besser eine alternative Formulierung für f verwenden, die die Variable x nur einmal verwendet. In diesem Fall kann man den Ausdruck f(x) = x2 + x einfach durch quadratische Ergänzung zu  umformen.
umformen.Dann liefert die entsprechende Intervallrechnung
auch den richtigen Wertebereich.
Im Allgemeinen lässt sich zeigen, dass man tatsächlich den genauen Wertebereich erhält, wenn jede Variable nur einmal auftaucht. Allerdings lässt sich nicht jede Funktion geeignet auflösen.
 Einhüllungs- oder „Wrapping“-Effekt
Einhüllungs- oder „Wrapping“-EffektDie durch das Abhängigkeitsproblem verursachte Überschätzung des Wertebereiches kann soweit gehen, dass das Resultat einen derart großen Bereich umfasst, der keine sinnvollen Schlüsse mehr zulässt.
Eine zusätzliche Vergrößerung des Wertebereichs ergibt sich aus dem Einhüllen von Bereichen, die nicht die Form eines Intervallvektors haben. Die Lösungsmenge des linearen Systems
 für
für ![p\in [-1,1]](1/ad18f8dce0b1026566b9d1823dfc85b3.png)
ist genau die Gerade zwischen den Punkten ( − 1, − 1) und (1,1). Intervallmethoden liefern hier aber im besten Fall das Quadrat
![[-1,1] \times [-1,1]](d/afd6932f58971a6eabd42f45e3009223.png) , das die tatsächliche Lösung einhüllt (Einhüllungs- oder „Wrapping“-Effekt).
, das die tatsächliche Lösung einhüllt (Einhüllungs- oder „Wrapping“-Effekt).Lineare Intervallsysteme
Ein lineares Intervallsystem besteht aus einer intervallwertigen Matrix
![[\mathbf{A}] \in [\mathbb{R}]^{n\times m}](e/f1e86feb666ed1a792ee61bff049bc86.png) und einem Intervallvektor
und einem Intervallvektor ![[\mathbf{b}] \in [\mathbb{R}]^{n}](b/e0b3f09fb10593b10cff3170aea0e5a7.png) . Gesucht ist dann eine möglichst schmale Box
. Gesucht ist dann eine möglichst schmale Box ![[\mathbf{x}] \in [\mathbb{R}]^{m}](a/f0a5f6da565fc0cb4be6ee5ff706705c.png) , die alle Vektoren
, die alle Vektoren  enthält, für die es ein Paar
enthält, für die es ein Paar  mit
mit ![\mathbf{A} \in [\mathbf{A}]](f/e3fa944da7d0f11651218f24ee109bda.png) und
und ![\mathbf{b} \in [\mathbf{b}]](6/e2664de77b97ae751ad4aa5902336959.png) gibt, das die Gleichung
gibt, das die Gleichungerfüllt.
Für quadratische Systeme - also für n = m - lässt sich ein solcher Intervallvektor
, der alle möglichen Lösungen enthält, sehr einfach mit dem Intervall-Gauß-Verfahren bestimmen. Hierfür ersetzt man die numerischen Operationen, die bei dem aus der linearen Algebra bekannten gaußschen Eliminationsverfahren auftauchen, durch ihre Intervallversionen. Da allerdings während der Abarbeitung dieser Methode die intervallwertigen Einträge von ![[\mathbf{A}]](d/f2d730150df919c88576ff1ea239a407.png) und
und ![[\mathbf{b}]](5/c95638f0ce99d7881e0a95cd180de928.png) mehrfach in die Rechnung eingehen, leidet dieser Ansatz sehr stark an dem Abhängigkeitsproblem. Folglich bietet sich der Intervall-Gauß nur für grobe erste Abschätzungen an, die zwar die gesamte Lösungsmenge enthalten, aber auch einen sehr großen Bereich außerhalb davon.
mehrfach in die Rechnung eingehen, leidet dieser Ansatz sehr stark an dem Abhängigkeitsproblem. Folglich bietet sich der Intervall-Gauß nur für grobe erste Abschätzungen an, die zwar die gesamte Lösungsmenge enthalten, aber auch einen sehr großen Bereich außerhalb davon.Eine grobe Lösung
kann oft durch eine Intervallisierung des Gauß-Seidel-Verfahrens verbessert werden. Diese ist folgendermaßen motiviert: Die i-te Zeile der intervallwertigen linearen Gleichunglässt sich nach der Variablen xi auflösen, falls die Division 1 / [aii] erlaubt ist. Es gilt demnach gleichzeitig
![x_j \in [x_j]](9/5a9023c2e84f663400d364bbc8a2d417.png) und
und ![x_j \in \frac{[b_i]- \sum\limits_{k \not= j} [a_{ik}] \cdot [x_k]}{[a_{ij}]}](f/1bf9c5907817c383d23112f32cc7ffb9.png) .
.
Man kann also nun [xj] durch
ersetzen, und so den Vektor
elementweise verbessern. Da das Verfahren effizienter für diagonaldominante Matrizen ist, versucht man oft statt dem System ![[\mathbf{A}]\cdot \mathbf{x} = [\mathbf{b}]\mbox{,}](a/05acc5dc4cd29ee0f46ab286672c7d51.png) die durch Multiplikation mit einer geeigneten reellen Matrix
die durch Multiplikation mit einer geeigneten reellen Matrix  entstandene Matrixgleichung
entstandene Matrixgleichungzu lösen. Wählt man beispielsweise
 für die Mittelpunktsmatrix , so ist
für die Mittelpunktsmatrix , so ist ![\mathbf{M} \cdot[\mathbf{A}]](f/00f18836d5891b8f7ae9ab2a17162b7f.png) eine äußere Näherung der Einheitsmatrix.
eine äußere Näherung der Einheitsmatrix.Für die oben genannten Methoden gilt allerdings, dass sie nur dann gut funktionieren, wenn die Breite der vorkommenden Intervalle hinreichend klein ist. Für breitere Intervalle kann es sinnvoll sein, ein Intervall-lineares System auf eine endliche (wenn auch große) Anzahl reellwertiger linearer Systeme zurückzuführen. Sind nämlich alle Matrizen
invertierbar, so ist es vollkommen ausreichend, alle möglichen Kombinationen an (oberen und unteren) Endpunkten der vorkommenden Intervalle zu betrachten. Die resultierenden Teilprobleme können dann mit herkömmlichen numerischen Methoden gelöst werden. Intervallarithmetik wird lediglich noch benutzt, um Rundungsfehler zu bestimmen.Dieser Ansatz ist allerdings nur für Systeme kleinerer Dimension möglich, da bei einer vollbesetzten
 Matrix schon
Matrix schon  reelle Matrizen invertiert werden müssen, mit jeweils 2n Vektoren für die rechte Seite. Dieser Ansatz wurde von Jiří Rohn noch weitergeführt und verbessert [1].
reelle Matrizen invertiert werden müssen, mit jeweils 2n Vektoren für die rechte Seite. Dieser Ansatz wurde von Jiří Rohn noch weitergeführt und verbessert [1].Intervall-Newton Verfahren
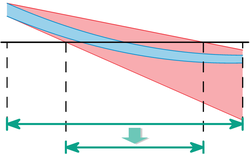 Reduktion des Suchgebietes im Intervall-Newton-Schritt bei „dicken“ Funktionen
Reduktion des Suchgebietes im Intervall-Newton-Schritt bei „dicken“ FunktionenEine Intervallvariante des Newton-Verfahrens zur Bestimmung der Nullstellen in einem Intervallvektor
lässt sich einfach aus der Mittelwert-Erweiterung ableiten (Lit.: Hansen, 1992). Für einen unbekannten Vektor ![\mathbf{z}\in [\mathbf{x}]](4/5c404f37cc388d76819f604f050ea83f.png) gilt für ein festes , dass
gilt für ein festes , dass \cdot (\mathbf{z} - \mathbf{y})](e/88eaf04f5153083e8f4202cd3ad42edc.png) .
.
Für eine Nullstelle
 ist f(z) = 0, und somit muss
ist f(z) = 0, und somit muss \cdot (\mathbf{z} - \mathbf{y})=0](f/49fd5cfe90d3be83aeca1c84f052ee9b.png) .
.
erfüllt sein. Man erhält also
^{-1}\cdot f(\mathbf{y})](8/a680b1492a9739b3762cb449430e122f.png) . Eine äußere Abschätzung von
. Eine äußere Abschätzung von ^{-1}\cdot f(\mathbf{y}))](6/986766ec2600865a0eff701a1400ba5b.png) kann hierbei durch eines der linearen Verfahren bestimmt werden.
kann hierbei durch eines der linearen Verfahren bestimmt werden.In jedem Newton-Schritt wird nun ein grober Startwert
![[\mathbf{x}]\in [\mathbb{R}]^n](e/ebe916ae68801e6263e9dc4112c73e70.png) durch
durch ![[\mathbf{x}]\cap \left(\mathbf{y} - [J_f](\mathbf{[x]})^{-1}\cdot f(\mathbf{y})\right)](d/9ddc1c40d6339c23beb2bb12a8c5b164.png) ersetzt und so iterativ verbessert. Im Gegensatz zum klassischen Verfahren nähert sich diese Methode von außen den Nullstellen. Daher ist garantiert, dass das Ergebnis immer alle Nullstellen im Startwert enthält. Umgekehrt hat man bewiesen, dass f keine Nullstelle in hat, wenn der Newton-Schritt die leere Menge zurückliefert.
ersetzt und so iterativ verbessert. Im Gegensatz zum klassischen Verfahren nähert sich diese Methode von außen den Nullstellen. Daher ist garantiert, dass das Ergebnis immer alle Nullstellen im Startwert enthält. Umgekehrt hat man bewiesen, dass f keine Nullstelle in hat, wenn der Newton-Schritt die leere Menge zurückliefert.Das Verfahren konvergiert gegen eine Menge, die alle Nullstellen (innerhalb der Startregion) enthält. Durch in diesem Fall vorhandene Divisionen durch Null entstehen oft mehrere Intervallvektoren, die die Nullstellen voneinander trennen. Diese Trennung ist nicht immer vollständig, und kann dann durch Bisektion forciert werden.
Als Beispiel betrachte man die Funktion f(x) = x2 − 2, den Startwert [x] = [ − 2,2] und den Punkt y = 0. Man hat dann
 und der erste Newton-Schritt ist gegeben durch
und der erste Newton-Schritt ist gegeben durch![[-2,2]\cap \left(0 - \frac{1}{2\cdot[-2,2]} (0-2)\right) = [-2,2]\cap \Big([{-\infty}, {-0.5}]\cup [{0.5}, {\infty}] \Big)](b/9bbc23f9b37750cbd3b8913303c90363.png) .
.
Es gilt also für eine Nullstelle
![x\in [{-2}, {-0.5}]\cup \big[{0.5}, {2}\big]](1/bf18fb51d82dfbfca62181002829a84b.png) . Weitere Newtonschritte werden dann jeweils auf
. Weitere Newtonschritte werden dann jeweils auf ![x\in [{-2}, {-0.5}]](5/3451fd8bfe3977ebc244ed06e1e98a13.png) und [0.5,2] getrennt angewendet. Diese konvergieren zu beliebig kleinen Intervallen um
und [0.5,2] getrennt angewendet. Diese konvergieren zu beliebig kleinen Intervallen um  und
und  .
.Das Intervall-Newton-Verfahren lässt sich auch ohne weiteres bei dicken Funktionen anwenden, also Funktionen wie g(x) = x2 − [2,3], die bereits dann Intervalle zurückliefern, wenn man reelle Zahlen einsetzt. Die Lösung besteht dann aus mehreren Intervallen
![\left[-\sqrt{3},-\sqrt{2} \right] \cup \left[\sqrt{2},\sqrt{3} \right]](7/047e3574d1bea20de15513ff3e07a527.png) .
.Bisektion und Überdeckungen
Die verschiedenen Intervallmethoden liefern nur äußerst konservative Abschätzungen eines jeweils gesuchten Bereiches, da Abhängigkeiten zwischen den intervallwertigen Größen nicht ausreichend berücksichtigt werden. Das Abhängigkeitsproblem spielt aber eine desto geringere Rolle, je dünner die Intervalle sind.
Überdeckt man einen Intervallvektor
durch kleinere Boxen ![[\mathbf{x}_1], \cdots , [\mathbf{x}_k]\mbox{,}](6/19667ef0bc4351555cea727940a06948.png) so dass
so dass ![\textstyle [\mathbf{x}] = \bigcup_{i=1}^k [\mathbf{x}_i]\mbox{,}](f/e4f1ee326be01e41c4f1ea8d0d3fad76.png) dann gilt für den Wertebereich
dann gilt für den Wertebereich ![\textstyle f([\mathbf{x}]) = \bigcup_{i=1}^k f([\mathbf{x}_i])\mbox{.}](a/cca879e2dfd1a23bcb1adc88a7db303e.png) Für die oben genannten Intervallerweiterungen gilt dann
Für die oben genannten Intervallerweiterungen gilt dann  \supseteq \bigcup_{i=1}^k [f]([\mathbf{x}_i])](1/041d2a00830cbc47051f4e46a0620a28.png) . Da
. Da ](3/e136764223f41a119f0bd9d84fc01eb4.png) oft eine echte Obermenge der rechten Seite ist, erhält man somit meist eine verbesserte Abschätzung.
oft eine echte Obermenge der rechten Seite ist, erhält man somit meist eine verbesserte Abschätzung. Überschätzung (türkis) und verbesserte Abschätzung durch „Mincing“ (rot)
Überschätzung (türkis) und verbesserte Abschätzung durch „Mincing“ (rot)Eine solche Überdeckung kann zum einen durch Bisektion generiert werden, indem man besonders dicke Elemente [xi1,xi2] des Intervallvektors
![[\mathbf{x}] = ([x_{11}, x_{12}], \cdots, [x_{n1}, x_{n2}])](d/67df2a7580d624e91567ed5b45018915.png) beispielsweise in der Mitte teilt und durch zwei Intervalle [xi1,(xi1 + xi2) / 2] und [(xi1 + xi2) / 2,xi2] ersetzt. Sollte das daraus folgende Resultat immer noch nicht geeignet sein, kann sukzessive weiter zerlegt werden. Hierbei gilt allerdings zu beachten, dass durch r geteilte Vektorelemente eine Überdeckung aus 2r Intervallvektoren entsteht, was den Rechenaufwand natürlich stark erhöht.
beispielsweise in der Mitte teilt und durch zwei Intervalle [xi1,(xi1 + xi2) / 2] und [(xi1 + xi2) / 2,xi2] ersetzt. Sollte das daraus folgende Resultat immer noch nicht geeignet sein, kann sukzessive weiter zerlegt werden. Hierbei gilt allerdings zu beachten, dass durch r geteilte Vektorelemente eine Überdeckung aus 2r Intervallvektoren entsteht, was den Rechenaufwand natürlich stark erhöht.Bei sehr breiten Intervallen kann es sogar sinnvoll sein, alle Intervalle gleich in mehrere Teilintervalle mit (kleiner) konstanter Breite zu zerlegen („Mincing“). Damit spart man die Zwischenrechnung für die einzelnen Bisektionsschritte. Beide Herangehensweisen sind allerdings nur für Probleme niedriger Dimension geeignet.
Anwendung
Die Intervallarithmetik kommt auf verschiedenen Gebieten zum Einsatz, um Größen zu behandeln, für die keine genauen Zahlenwerte festgelegt werden können (Lit.: Jaulin et. al., 2001).
Rundungsfehleranalyse
Die Intervallarithmetik wird bei der Fehleranalyse angewendet, um Kontrolle über die bei jeder Berechnung auftretenden Rundungsfehler zu bekommen. Der Vorteil der Intervallarithmetik liegt darin, dass man nach jeder Operation ein Intervall erhält, welches das Ergebnis sicher einschließt. Aus dem Abstand der Intervallgrenzen kann man den aktuellen Berechnungsfehler direkt ablesen:
- Fehler = abs(a − b) für gegebenes Intervall [a,b].
Intervallanalyse bietet hierbei keinen Ersatz für die klassischen Methoden zur Fehlerreduktion, wie Pivotisierung, sondern ergänzt diese lediglich.
Toleranzanalyse
Bei der Simulation technischer und physikalischer Prozesse treten oft Parameter auf, denen keine exakten Zahlenwerte zugeordnet werden können. So unterliegt der Produktionsprozess technischer Bauteile gewissen Toleranzen, so bestimmte Parameter innerhalb bestimmter Intervalle schwanken können. Außerdem können viele Naturkonstanten nicht mit beliebiger Genauigkeit gemessen werden (Lit.: Dreyer, 2005).
Wird das Verhalten eines solchen toleranzbehafteten Systems beispielsweise durch eine Gleichung
 , für
, für ![\mathbf{p} \in [\mathbf{p}]](9/459b42e193eef3933c7c89b0026a77ea.png) und Unbekannten , beschrieben, dann kann die Menge aller möglichen Lösungen
und Unbekannten , beschrieben, dann kann die Menge aller möglichen Lösungen![\{\mathbf{x}\,|\, \exists \mathbf{p} \in [\mathbf{p}], f(\mathbf{x}, \mathbf{p})= 0\}](0/410a53529a26b8cb37bbb3cf743d24c4.png) ,
,
durch Intervallmethoden abgeschätzt werden. Diese stellen hier eine Alternative zur klassischen Fehlerrechnung dar. Im Gegensatz zu punktbasierten Methoden, wie der Monte-Carlo-Simulation, stellt die verwendete Methodik sicher, dass keine Teile des Lösungsgebietes übersehen werden. Allerdings entspricht das Ergebnis immer einer Worst Case-Analyse für gleichverteilte Fehler, andere Wahrscheinlichkeitsverteilungen sind nicht möglich.
Fuzzy-Arithmetik
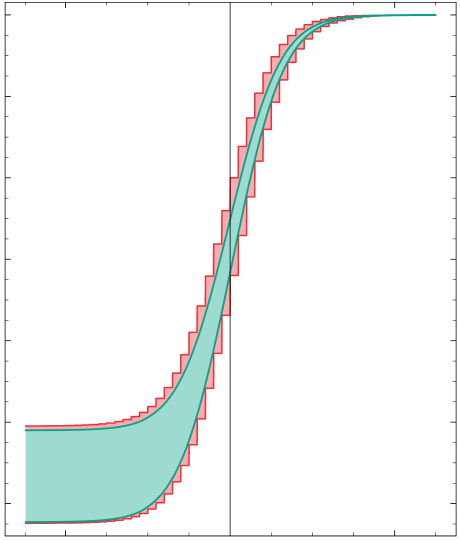
 Approximation der Normalverteilung durch eine Sequenz von Intervallen
Approximation der Normalverteilung durch eine Sequenz von IntervallenIntervallarithmetik kann auch dazu verwendet werden, beliebige Zugehörigkeitsfunktionen für unscharfe Mengen wie sie in der Fuzzy-Logik benutzt werden anzunähern. Neben den strikten Aussagen
![x\in [x]](0/d8009fa9f097e64b39d03d092bfc6524.png) und
und ![x \not\in [x]](7/2b753c6b8e83bee2ce43de68280d93d4.png) sind hier auch Zwischenwerte möglich, denen reelle Zahlen
sind hier auch Zwischenwerte möglich, denen reelle Zahlen ![\mu \in [0,1]](c/40c22bb74ef18fef1869b28e9a8a702b.png) zugeordnet werden. Dabei entspricht μ = 1 der sicheren Zugehörigkeit und μ = 0 der Nichtzugehörigkeit. Eine Verteilungsfunktion ordnet jedem dieser Werte einen gewissen Schwankungsbereich zu, den man wieder als Intervall auffassen kann.
zugeordnet werden. Dabei entspricht μ = 1 der sicheren Zugehörigkeit und μ = 0 der Nichtzugehörigkeit. Eine Verteilungsfunktion ordnet jedem dieser Werte einen gewissen Schwankungsbereich zu, den man wieder als Intervall auffassen kann.Für die Fuzzy-Arithmetik[2] werden nur endlich viele diskrete Zugehörigkeitsstufen
![\mu_i \in [0,1]](d/e3dfb6877e8939cabfbecd1f98528776.png) betrachtet. Die Form einer solchen Verteilung für einen unscharfen Wert kann dann durch eine Reihe von Intervallen
betrachtet. Die Form einer solchen Verteilung für einen unscharfen Wert kann dann durch eine Reihe von Intervallenangenähert. Dabei entspricht das Intervall [x(i)] genau dem Schwankungsbereich für die Stufe μi.
Die entsprechende Verteilung für eine Funktion
bezüglich unscharfer Werte  und den entsprechenden Sequenzen
und den entsprechenden Sequenzen ![\left[x_1^{(1)} \right] \supset \cdots \supset \left[x_1^{(k)} \right], \cdots ,
\left[x_n^{(1)} \right] \supset \cdots \supset \left[x_n^{(k)} \right]](2/d0275ea3deb441cdcc54f784cebc91fb.png) lässt sich dann durch die Intervallsequenz
lässt sich dann durch die Intervallsequenz ![\left[y^{(1)}\right] \supset \cdots \supset \left[y^{(k)}\right]](2/8c21f393e9c2afdd4adc4bc5cda71ba2.png) approximieren. Die Werte
approximieren. Die Werte ![\left[y^{(i)}\right]](4/d945d27b31ba1ed550beca968f2cf942.png) sind gegeben durch
sind gegeben durch ![\left[y^{(i)}\right] = f \left( \left[x_{1}^{(i)}\right], \cdots \left[x_{n}^{(i)}\right]\right)](a/8ba6aaf24f12373bef2fe3860ea6a8c8.png) und können durch Intervallverfahren abgeschätzt werden. Dabei entspricht
und können durch Intervallverfahren abgeschätzt werden. Dabei entspricht ![\left[y^{(1)}\right]](a/7da8958c81b37074e715d58d252ce0f5.png) dem Ergebnis einer Intervallrechnung.
dem Ergebnis einer Intervallrechnung.Geschichtliches
Intervallarithmetik ist keine völlig neue Erscheinung in der Mathematik und tauchte bereits mehrfach unter verschiedenen Namen im Laufe der Geschichte auf. So berechnete Archimedes bereits im 3. Jahrhundert v. Chr. obere und untere Schranken für die Kreiszahl Pi. Allerdings wurde das eigentliche Rechnen mit Intervallen nie so populär wie andere numerische Techniken, wurde aber nie völlig vergessen.
Regeln für das Rechnen mit Intervallen und anderen Teilmengen der reellen Zahlen finden sich schließlich in einer 1931 veröffentlichten Arbeit von Rosalind Cicely Young, einer Doktorandin an der Universität Cambridge. Arbeiten für eine Arithmetik von range numbers („Bereichszahlen“) in Hinblick auf eine Verbesserung und Zuverlässigkeit digitaler Systeme finden sich dann in einem 1951 veröffentlichten Lehrbuch zur linearen Algebra von Paul S. Dwyer (University of Michigan). Hier werden Intervalle tatsächlich dafür eingesetzt, die Rundungsfehler bei Gleitkommazahlen abzuschätzen.
Als Geburtsstunde der modernen Intervallarithmetik wird das Erscheinen des Buches Interval Analysis von Ramon E. Moore im Jahr 1966 (Lit.: Moore) angesehen. Die Idee dazu hatte er im Frühjahr 1958, und bereits ein knappes Jahr später veröffentlichte er einen Artikel über computerunterstützte Intervallarithmetik [3]. Sein Verdienst ist es, dass aus einem einfachen Prinzip eine allgemeingültige Methode zur automatisierten Fehleranalyse wurde, mit deren Hilfe nicht nur der Einfluss von Rundungen bestimmt werden konnte.
Unabhängig davon hatte Mieczyslaw Warmus zwar schon 1956 Formeln für das Rechnen mit Intervallen vorgeschlagen [4], bei Moore fanden sich aber neben Implementierungshinweisen auch erste nicht-triviale Anwendungen.
In den folgenden zwanzig Jahren leisten deutsche Forschergruppen um Götz Alefeld (Lit.: Alefeld und Herzberger) und Ulrich Kulisch (Lit.: Kulisch) an der Universität Karlsruhe und später auch an der Bergischen Universität Wuppertal Pionierarbeit. Beispielsweise erforschte Karl Nickel effizientere Implementierungen, während man verbesserte Eingrenzungsverfahren für die Lösungsmenge von Gleichungssystemen unter anderen Arnold Neumaier verdankt[5]. Auch Eldon R. Hansen beschäftigte sich zunächst in den 60ern mit intervallwertigen linearen Gleichungen und lieferte später dann entscheidende Beiträge zur globalen Optimierung (Lit.: Hansen). Auf diesem Gebiet wird versucht, mit Intervallen das Problem anzugehen, dass mit der klassischen Numerik oft nicht der größte (oder kleinste) Funktionswert bestimmt werden kann, sondern nur ein sogenanntes lokales Optimum an einer Stelle, in deren Umgebung keine besseren Werte angenommen werden. Hierfür übertrugen Ratschek und Rokne das Branch-and-Bound-Verfahren, das ursprünglich nur für ganzzahlige Werte definiert war, mit Hilfe von Intervallverfahren auf kontinuierliche Größen[6]. Im Jahr 1988 entwickelte Rudolf Lohner eine Fortran-basierte Software für sichere Lösungen für Anfangswertaufgaben bei gewöhnliche Differentialgleichungen. [7]
Seit den 90ern wird das Journal Reliable Computing (ursprünglich Interval Computations) herausgegeben, das sich der Zuverlässigkeit computerunterstützter Berechnungen widmet. Als leitender Redakteur hat R. Baker Kearfott neben seinen Arbeiten zur globalen Optimierung wesentlich zur Vereinheitlichung der Notation und Begrifflichkeiten der Intervallarithmetik beigetragen (Web: Kearfott).
In jüngerer Zeit sind insbesondere die Arbeiten zur Abschätzung des Urbildes parametrisierter Funktionen und zur robusten Kontrolle von der COPRIN-Arbeitsgruppe des INRIA im französischen Sophia Antipolis zu erwähnen (Web: INRIA).
Patente
Einer der wesentlichen Förderer der Intervallarithmetik, G. William Walster von Sun Microsystems, hat in den Jahren 2003/04 – teilweise zusammen mit Ramon E. Moore und Eldon R. Hansen – mehrere Patente im Bereich der Intervallarithmetik beim U.S. Patent and Trademark Office angemeldet [8]. Die Gültigkeit dieser Ansprüche ist jedoch in der Intervallarithmetik-Forschungsgemeinde stark umstritten, da sie möglicherweise lediglich den bisherigen Stand der Technik wiedergeben.
Implementierungen
Es gibt viele Softwarepakete, welche die Entwicklung numerischer Anwendungen unter Nutzung der Intervallarithmetik erlauben [9]. Diese sind meist in Form von Programmbibliotheken umgesetzt [10]. Es gibt allerdings auch C++- und Fortran-Übersetzer, welche Intervall-Datentypen und entsprechend geeignete Operationen als Spracherweiterung [11] besitzen, so dass Intervallarithmetik direkt unterstützt wird.
Seit 1967 entwickelte man zunächst an der Universität Karlsruhe XSC-Erweiterungen für wissenschaftliches Rechnen („Extensions for Scientific Computation“) für verschiedene Programmiersprachen, darunter C++, Fortran und Pascal [12]. Plattform war zunächst ein Zuse Z 23, für den ein neuer Intervall-Datentyp mit entsprechenden elementaren Operatoren zur Verfügung gestellt wurde.
1976 folgte mit Pascal-SC eine Pascal-Variante auf einem Zilog Z80, die es ermöglichte, schnell komplexe Routinen für automatisierte Ergebnisverifikation zu schaffen. Es folgte das Fortran 77-basierte ACRITH-XSC für die System/370-Architektur, das später auch von IBM ausgeliefert wird. Ab 1991 kann man mit Pascal-XSC dann Code für C-Compiler erzeugen, und ein Jahr später unterstützt die C++-Klassenbibliothek C-XSC bereits viele verschiedene Computersysteme. 1997 werden alle XSC-Varianten unter die General Public License gestellt und stehen so frei zu Verfügung. Anfang der 2000er-Jahre wurde C-XSC 2.0 unter Federführung der Arbeitsgruppe für wissenschaftliches Rechnen an der Bergischen Universität Wuppertal neugestaltet, um dem mittlerweile verabschiedeten C++-Standard besser entsprechen zu können.
Eine weitere C++-Klassenbibliothek ist das 1993 an der TU Hamburg-Harburg geschaffene Profil/BIAS („Programmer's Runtime Optimized Fast Interval Library, Basic Interval Arithmetic“), das die üblichen Intervalloperationen benutzerfreundlich zur Verfügung stellt. Dabei wurde besonderen Wert auf die effiziente Ausnutzung der Hardware, Portabilität und Unabhängigkeit von einer speziellen Intervalldarstellung gelegt.
Die Boost-Sammlung von C++-Bibliotheken enthält ebenfalls eine Template-Klasse für Intervalle. Deren Autoren bemühen sich derzeit um eine Aufnahme der Intervallarithmetik in den C++-Sprachstandard [13].
Heute können außerdem die gängigen Computeralgebrasysteme, wie Mathematica, Maple und MuPAD, mit Intervallen umgehen. Außerdem gibt es für Matlab die Erweiterung Intlab, die auf BLAS-Routinen aufbaut, sowie die Toolbox b4m, die ein Profil/BIAS-Interface zur Verfügung stellt[14].
Siehe auch
- Automatisches Differenzieren (Automatic differentiation in der englischsprachigen Wikipedia)
- Mehrgitterverfahren
- Monte-Carlo-Simulation
IEEE-Standard P1788
Ein IEEE-Standard für Intervallarithmetik [15] wird zur Zeit entwickelt.
Referenzen
Literatur
- Götz Alefeld und Jürgen Herzberger: Einführung in die Intervallrechnung. Bibliographisches Institut, Reihe Informatik, Band 12, B.I.-Wissenschaftsverlag, Mannheim - Wien - Zürich, ISBN 3-411-01466-0
- Alexander Dreyer: Interval Analysis of Analog Circuits with Component Tolerances. Doktorarbeit, Shaker Verlag, Aachen, 2003, ISBN 3-8322-4555-3.
- Eldon Hansen und G. William Walster: Global Optimization using Interval Analysis, Second Edition, Revised and Expanded, Marcel Dekker, New York, 2004, ISBN 0-8247-4059-9.
- L. Jaulin, M. Kieffer, O. Didrit, and É.Walter: Applied Interval Analysis: With examples in parameter estimation robust control and robotics. Springer, London, 2001, ISBN 1-85233-219-0.
- Ulrich Kulisch: Wissenschaftliches Rechnen mit Ergebnisverifikation. Eine Einführung, Vieweg-Verlag, Wiesbaden 1989, ISBN 3-528-08943-1.
- R. E. Moore: Interval Analysis. Prentice-Hall, Englewood Cliff, NJ, 1966, ISBN 0-13-476853-1.
Weblinks
- Brian Hayes, 'A Lucid Interval', gute Einführung (pdf) (83 kB)
- Einführender Film (mpeg) des COPRIN Teams des INRIA, Sophia Antipolis
- Bibliographie von R. Baker Kearfott, University of Louisiana, Lafayette
- Bibliographie von Arnold Neumaier, Universität Wien
Quellen
- ↑ Veröffentlichungen von Jiří Rohn
- ↑ Fuzzy-Methoden, Zusammenstellung von Michael Hanss, Universität Stuttgart
- ↑ Abhandlung über frühe Artikel von R. E. Moore
- ↑ Frühe Arbeiten von M. Warmus
- ↑ Veröffentlichungen von Arnold Neumaier
- ↑ Veröffentlichungen von Jon Rokne
- ↑ Einschließungen gewöhnlicher Differentialgleichungen nach Rudolf Lohner
- ↑ Patentschriften unter Anwendung von Intervallarithmetik beim U.S. Patent and Trademark Office
- ↑ Software für Intervallrechnungen, zusammengestellt von Vladik Kreinovich, University of Texas, El Paso
- ↑ Beispiel einer Intervallarithmetik-Klasse in C++ von Sun Microsystems
- ↑ C++- und Fortran-Compiler mit Intervallunterstützung von Sun Microsystems
- ↑ Geschichte der XSC-Erweiterungen
- ↑ Vorschlag für eine Erweiterung der C++-Standards um Intervalle
- ↑ INTerval LABoratory und b4m
- ↑ IEEE Interval Standard Working Group - P1788
Kategorien:- Arithmetik
- Computerarithmetik
- Numerische Mathematik


![[79{,}5; 80{,}5]/([1{,}795; 1{,}805])^2 = [24{,}4; 25{,}0]\,](c/19cc52ffc14ccfd3cd1a564e19e8eb45.png)
![[x_1, x_2] {\,\langle\!\mathrm{op}\!\rangle\,} [y_1, y_2] =
\{ x {\,\langle\!\mathrm{op}\!\rangle\,} y \, | \, x \in [x_1, x_2] \,\mbox{und}\, y \in [y_1, y_2] \}](7/cb742ad1ee85e8f683cb0a878dea4833.png)
![\begin{matrix}[x_1, x_2]{\,\langle\!\mathrm{op}\!\rangle\,} [y_1, y_2] & = & {\left[ \min(x_1 {\langle\!\mathrm{op}\!\rangle} y_1, x_1{\langle\!\mathrm{op}\!\rangle} y_2, x_2 {\langle\!\mathrm{op}\!\rangle} y_1, x_2 {\langle\!\mathrm{op}\!\rangle} y_2),
\right.}\\
&& {\left.
\;\max(x_1 {\langle\!\mathrm{op}\!\rangle}y_1, x_1 {\langle\!\mathrm{op}\!\rangle} y_2, x_2
{\langle\!\mathrm{op}\!\rangle} y_1, x_2 {\langle\!\mathrm{op}\!\rangle} y_2) \right]}
\,\mathrm{,}
\end{matrix}](4/634084db731732a7091133d63844f3f0.png)
![[\mathbb{R}] := \big\{\, [x_1, x_2] \,|\, x_1 \leq x_2 \,\mbox{und}\, x_1, x_2 \in \mathbb{R} \cup \{-\infty, \infty\} \big\}](6/ee6d12d82ba1b8fe8d690b809c3e2e7a.png)




![\left([-1,1] + \frac{1}{2}\right)^2 -\frac{1}{4} =
\left[-\frac{1}{2}, \frac{3}{2}\right]^2 -\frac{1}{4} = \left[0, \frac{9}{4}\right] -\frac{1}{4} = \left[-\frac{1}{4},2\right]](a/eaabcfe1b5e33f46c3876f6107b92946.png)


![\begin{pmatrix}
{[a_{11}]} & \cdots & {[a_{1n}]} \\
\vdots & \ddots & \vdots \\
{[a_{n1}]} & \cdots & {[a_{nn}]}
\end{pmatrix}
\cdot
\begin{pmatrix}
{x_1} \\
\vdots \\
{x_n}
\end{pmatrix}
=
\begin{pmatrix}
{[b_1]} \\
\vdots \\
{[b_n]}
\end{pmatrix}](5/f352e90bbf4babc7da2eb1dd71821cba.png)
![[x_j] \cap \frac{[b_i]- \sum\limits_{k \not= j} [a_{ik}] \cdot [x_k]}{[a_{ij}]}](3/243940dd76bfb535bb8133634104e620.png)
![(\mathbf{M}\cdot[\mathbf{A}])\cdot \mathbf{x} = \mathbf{M}\cdot[\mathbf{b}]](f/a7f0ef30a39b6242836b8f6b652a20a2.png)



![\left[x^{(1)}\right] \supset \left[x^{(2)}\right] \supset \cdots \supset \left[x^{(k)} \right]](3/cc3fef7681917047a17bc3a53bf79830.png)
Wikimedia Foundation.